Как рассчитать стандартное отклонение выборки и популяции?
- Несколько слов, чтобы напомнить вам, что такое стандартное отклонение
- Стандартное отклонение от образца
- Пример - когда стандартное отклонение выборки и когда популяции
- Таблицы и стандартное отклонение
- суммирование
«Помогите, помогите! Я считаю стандартное отклонение в Excel (или другой электронной таблице), и результат получается совершенно другим, чем я рассчитывал на калькуляторе, на листе бумаги или просто в моей голове. Где ошибка сидит, потому что я проверяю пятый раз, и она все равно выходит? "
Регулярные читатели статистики уже знают, что запись о стандартное отклонение это было давно, и они могут рассчитать такое отклонение. Но даже тогда я упомянул только что-то вроде стандартного отклонения от попытки , И подсчет именно такого отклонения должен быть осторожным, потому что схема отличается от стандартного отклонения в население ,
Несколько слов, чтобы напомнить вам, что такое стандартное отклонение
Напомним в начале, что такое стандартное отклонение. Это мера изменчивости распределения, которая он говорит о том, насколько значения проверяемой функции отклоняются от среднего арифметического. Большое стандартное отклонение информирует нас о том, что население очень разнообразно, а небольшое стандартное отклонение говорит о том, что отдельные единицы близки к среднему. Узор, напомню, выглядит так:
\ (S = \ SQRT {\ гидроразрыва {\ sum_ {= 1} ^ {N} (X_ {я} - \ Overline {х}) ^ {2}} {п}} = \ SQRT {\ гидроразрыва {( X_ {1} - \ Overline {х}) ^ {2} + (X_ {2} - \ Overline {х}) ^ {2} + \ ldots + (X_ {п} - \ Overline {х}) ^ {2 }}}} {п \)
Стандартное отклонение от образца
Вот как это выглядело в случае с населением. И как это будет выглядеть в случае судебного разбирательства? В паттерне мы имеем дело с одним маленьким крошечным изменением. А именно, в знаменателе дроби вместо n появляется (n-1) .
\ (S = \ SQRT {\ гидроразрыва {\ sum_ {= 1} ^ {N} (X_ {я} - \ Overline {х}) ^ {2}} {п-1}} = \ SQRT {\ гидроразрыва {(X_ {1} - \ Overline {х}) ^ {2} + (X_ {2} - \ Overline {х}) ^ {2} + \ ldots + (X_ {п} - \ Overline {х}) ^ } {2} {п-1}} \)
Что означает это изменение? На практике стандартное отклонение, рассчитанное по выборке (в случае тех же данных), будет немного больше, чем отклонение популяции. Чем больше выборка, тем больше будет размыт разрыв. В случае небольших выборок, особенно довольно разнообразных, изменение значения n на ( n-1 ) может существенно изменить результат.
Откуда разница в шаблонах? Почему ( n-1 )? При расчете стандартного отклонения образца можно ли использовать первую формулу только с n ? Помните, что, считая стандартное отклонение выборки, мы рассчитываем неизвестный параметр. Мы оцениваем значение стандартного отклонения для населения. Проще говоря, мы можем сказать, что мы знаем, что мы не знаем ни истинного среднего населения, ни истинного стандартного отклонения. Поэтому мы ожидаем, что истинное стандартное отклонение для населения будет отличаться от выборки (хотя бы потому, что мы используем расчетное среднее значение для его расчета, а не реальный параметр для всей популяции). И ожидая эту разницу, мы принимаем большее значение отклонения. Но если мы не планируем оценивать, то нам не нужно использовать формулу для статистической выборки. Итак, когда мы можем использовать формулу, в которой только n подсчитывает стандартное отклонение выборки? Затем, когда мы сознательно подсчитываем значение отклонения только для этой выборки и не планируем обобщать результат для всей совокупности. Мы не рассматриваем это как оценку для населения, но мы считаем параметр из выборки.
Пример - когда стандартное отклонение выборки и когда популяции
Теория Теория. Испытания, популяции, n , n-1 . Все перепутано, и трудно почувствовать это. Я думаю, что будет лучше, когда нам поможет сладкий пример:
- Я купил 20 печенья, и я хочу знать, сколько они весят и каково стандартное отклонение веса моих печенья. Меня интересуют только мои купленные печенья. Поэтому я использую первую формулу для стандартного отклонения в популяции.
- Я купил точно такие же 20 печенья, но я хочу знать, сколько они весят и какое стандартное отклонение они имеют для всех тортов из моих любимых кондитерских изделий. Я хочу знать, какова вероятность того, что в следующий раз я получу печенье большего или меньшего размера. Затем я использую вторую формулу для стандартного отклонения от образца.
- Я владелец кондитерской. Я взвешиваю и измеряю все печенье. Я могу точно сказать, каков средний вес печеного печенья. Я также могу рассчитать стандартное отклонение для всех файлов cookie. Я снова использую первую формулу для стандартного отклонения в популяции.
Таблицы и стандартное отклонение
И теперь мы приходим к тому, что было в начале. Наиболее распространенное использование в электронных таблицах функций «стандартное отклонение» или «стандартное отклонение» совершенно не осознает, что оно относится к стандартному отклонению выборки. Если мы хотим вычислить отклонение для совокупности, то мы должны использовать функцию «stdevp» или «стандартное отклонение» (примечание! В разных таблицах эти имена могут различаться - я настоятельно рекомендую вам внимательно прочитать описание функции перед использованием). Самая частая ловушка - это ручное вычисление стандартного отклонения для населения, и для проверки результата используйте функцию «stdev» на листе. Вот когда появляются различия и повторения - где мы можем пойти не так? Чтобы не дать себя одурачить - каждый раз стоит прочитать, что именно означает функция, которую мы намерены использовать.
суммирование
Я намеренно не упоминаю, что, считая стандартное отклонение выборки и используя формулу с одним n, мы должны были бы иметь дело со смещенной оценкой. Я не упоминаю, что ( n-1 ) означает несмещенную оценку отклонения (или стандартное отклонение также?). Я не упоминаю степени свободы и т. Д. Возможно, однажды я займусь записью, которая объяснит эти сложности, но на данный момент все те, кто больше интересуется этой темой, ссылаются на типичные умные учебники из статистики. И не удивляйтесь, если вы прочитаете где-нибудь, что все это было изобретено давно, и это действительно не имеет значения, если вы считаете n или n-1 . Иногда получается, что в статистике не все вопросы имеют только один очевидный ответ. И статистики могут также иметь разные мнения о том, когда использовать дизайн.
Чтобы напомнить себе, что уже было в статистике - я призываю вас использовать это оглавление , Быть в курсе событий - это нравится facebook , И лучше всего убедить нескольких коллег сделать это - потому что почему они устают только от статистики учебников, если вы можете усвоить ее в более приятной версии?
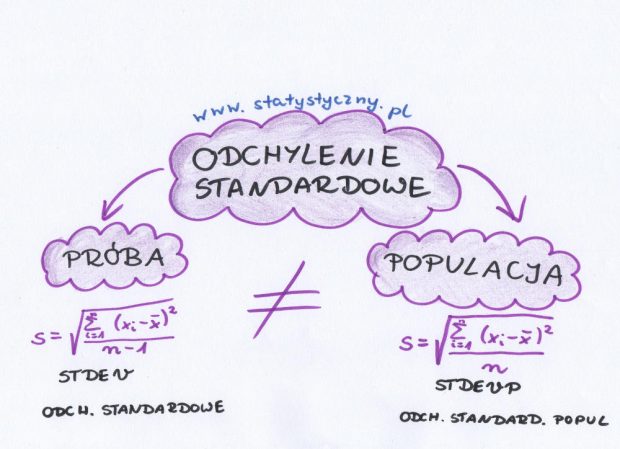
карта разума: стандартное отклонение выборки
Пожалуйста, следуйте и нам нравится:
Похожие
Что такое почвенный профиль?Профиль почвы Если бы кто-то мог вырыть массивную траншею (яму), примерно на 50-100 футов вертикально вниз, в землю, вы заметите, что вы бы пробили различные слои почвы. Взгляд на слои с расстояния дает поперечное сечение земли (под поверхностью) и вида почв и камней, из которых она состоит. Это поперечное сечение называется профилем почвы. Профиль состоит из слоев, проходящих Ценообразование - Как рассчитать розничную цену?
Прежде чем поставщик может предложить свой продукт для продажи третьим лицам, он должен установить цену продажи или предложить этот продукт, т.е. рассчитать цену. При определении цены продажи необходимо учитывать следующие вопросы: Какую цену покупатели готовы платить за товар? Какова цена других поставщиков, предлагающих аналогичный продукт? Какова стоимость самого Что такое технический анализ?
В отличие от фундаментального анализа, технический анализ является относительно новой дисциплиной, которая все еще совершенствуется его практиками. Тем не менее, годы постоянного использования сделали его неотъемлемой частью арсенала продавца: технические исследования, вероятно, являются единственным инструментом, используемым для определения точек входа или выхода, и, вкратце, технический анализ, вероятно, является единственным аналитическим инструментом, способным предвидеть. Технический Несколько слов о фракталах и их приложениях
... исследования, проведенные на кафедре теории вероятностей Института математики Силезского университета им. Петр Яношка. Несколько слов о фракталах и их приложениях "Увидеть мир в песчинке, Небеса в одном цветке из леса. Держи простор в своей сжатой руке, В час - бесконечное время Уильям Блейк В разговорном смысле мы называем фрактальный объект, части которого похожи на целое (самоподобные) или показывающие тонкие детали в многократном увеличении Что такое инсентив-туризм, мотивационный туризм, деловой туризм
Я думал, что в конце я сижу, собираю все мысли в одно связное целое, анализирую все знания, полученные за эти годы, и отвечаю как можно лучше на вопрос, Конвергенция колес - что это такое и как это влияет на вождение?
Отсутствие выравнивания колес, к сожалению, является распространенной проблемой. Часто бывает, что водитель неосознанно использует автомобиль с таким дефектом. Чаще всего это вызвано не халатностью, а невежеством. Что такое конвергенция колес и как это влияет на нашу машину? Что такое схождение колес? Проще говоря, это значение, которое определяет положение передних или задних колес относительно Как заказать курьер DPD
... когда не был таким простым. Как заказать курьера? Чтобы заказать курьера, все, что вам нужно, это компьютер или мобильное устройство с доступом в Интернет и принтером. форма оценки отгрузки введите параметры пакета, такие как его размер и вес, и выберите дополнительные параметры. Стоит обратить внимание на определение того, имеет ли груз правильную форму, то есть сортироваться и принять решение о страховании. Кроме стандартное отклонение для начинающих
... популяции. Это очень важная информация, потому что многие статистические гипотезы основаны на них, и мы вернемся к этой теме много раз. А что если мы знаем, что наше население не имеет ничего общего с нормальным распределением? Затем принимаются некоторые более строгие условия, вытекающие из неравенства Чебышева. Предполагается, что на расстоянии двух стандартных отклонений от среднего значения наблюдается 75% наблюдений, на расстоянии 3 отклонений - 88,89% наблюдений, на расстоянии Что означает слово «лазер»?
... иление света за счет вынужденного излучения. Но прежде чем мы начнем говорить о будущем лазеров (привет фазеры ), давайте посмотрим, где все это началось. Его развитие в 1960 году до сих пор считается одним из главных прорывов 20-го века. Знаете ли вы, что основание для лазера было сделано в начале 1950-х годов с MASER; AFOSR поддерживается Как украсить современный зал?
Хотите знать, как должен выглядеть идеальный зал в семейной квартире? Вы хотите изменить расположение ваших шкафов и полок? Black Red White предлагает, в какую мебель стоит инвестировать и на что обратить особое внимание при обустройстве современного прихожей. Коридор - это первая комната, которую вы видите сразу после пересечения порога дома. Здесь вы приветствуете и прощаетесь со своими гостями. Зал должен выглядеть хорошо и современно, Что такое работа в особых условиях или специального характера?
Процедуры по определению того, соответствует ли заинтересованная сторона условиям получения пособий по старости, инвалидности или досрочному выходу на пенсию, - в соответствии со ст. 115 Закона от 17 декабря 1998 года о пенсиях из Фонда социального страхования (сводный текст «Вестник законов 2016 года», пункт 887, с изменениями) и ст. 68 Закона от 13 октября 1998 года о системе социального обеспечения (сводный текст «Вестник законов» за 2016 год, пункт 963 с изменениями) - в компетенцию организационных
Комментарии
Несколько слов о пенсиях что, как, почему?Несколько слов о пенсиях что, как, почему? Тема реки и часто вызывает споры. Почему стоит поговорить? Потому что, к сожалению, мы не всегда заботимся о нашем будущем. Это часто слишком далекие времена для нас. Работа моряка специфична. В большинстве случаев это не гарантирует выход на пенсию или обеспечение в случае аварии и т. Д. Смело пишите в комментариях, как вы справляетесь с этой ситуацией. Может быть, у вас Что такое среднее значение и как его можно рассчитать?
Что такое среднее значение и как его можно рассчитать? Его значение всегда очевидно? Карта разума: среднее арифметическое Среднее арифметическое получается путем суммирования значений всех проверенных объектов и деления этой суммы Не ошибся ли Джон Барт, когда написал двадцать лет назад, что традиционное чтение достаточно интерактивно, что оно является своеобразным представлением, которое позволяет ему расти?
Не ошибся ли Джон Барт, когда написал двадцать лет назад, что традиционное чтение достаточно интерактивно, что оно является своеобразным представлением, которое позволяет ему расти? Возможно, маргинальный характер этого типа практики доказывает, что Барт, однако, был прав и неправ Лобин, писавший об исчезновении деления на автора и читателя в галактике Энгельбарта. Возможно, огромный успех романа «Девушка онлайн» Зои Сугг - как выяснилось, на самом деле был написан командой, создающей Что делать, если вам нужно что-то, что умещается в одной руке?
Что делать, если вам нужно что-то, что умещается в одной руке? ZTE тебя прикрыл. Здесь в IFA 2016 ZTE только что официально анонсировала Axon 7 Mini. С более компактным экраном, чуть меньшими характеристиками и почти таким же дизайном, как у его старшего брата, Axon 7 Mini нацеливается на море других компаний среднего уровня на рынке. Вот все, что вам нужно знать о ZTE Axon 7 Mini. ZTE Axon 7 Мини дизайн Означает ли это, что Таро такое же, как, например, игральные карты, которые выросли из него?
Означает ли это, что Таро такое же, как, например, игральные карты, которые выросли из него? Так совершенно обыденно? Нет, это не то же самое. Но именно поэтому это необычный инструмент, служащий не только для раскрытия секретов прошлого и будущего человека, но и для его души. Таро было, есть и останется загадкой Считается, что его символы содержат зашифрованную историю Вселенной. Таро обнаруживает связи между макрокосмом и микрокосмом. Описывает отношения между Как фотографировать в помещении, как бороться с искусственным освещением, как делать хорошие фотографии в помещении, фотографироваться со вспышкой или без нее?
Как фотографировать в помещении, как бороться с искусственным освещением, как делать хорошие фотографии в помещении, фотографироваться со вспышкой или без нее? Конечно, у вас все еще есть несколько вопросов, которые вы можете легко добавить здесь, и польский интернет молчит. Так в чем же секрет удачных фотографий в интерьерах? Сегодня я постараюсь рассмотреть многие ситуации и представить простые решения. Я надеюсь, что каждый любитель фотографии найдет здесь ответы. Фотографии в комнатах Что такое Amazon Echo и как оно работает?
Что такое Amazon Echo и как оно работает? Давайте начнем с самого начала. Amazon представила интеллектуальный динамик Echo в конце 2014 года. Это автономный динамик Bluetooth с набором микрофонов «дальнего поля», которые могут слышать вас на умеренном расстоянии, а также соединение Wi-Fi с облаком Amazon. Вы просыпаете «Эхо», произнося «Алекса», имя виртуального помощника Амазонки ( Вы можете изменить Так как защитить себя от покупки новой мебели и что делать, чтобы она была свежей?
Так как защитить себя от покупки новой мебели и что делать, чтобы она была свежей? Они спасение мебельный шпон Благодаря этому мы сможем быстро и дешево обновить мебель. Нетрудно починить мебель, и с небольшой точностью и добросовестностью каждый может справиться с этим. О том, как подготовиться к покрытию мебели и как сделать это шаг за шагом, мы написали в нашей записи Что ж, давайте будем честными, что еще в этом телефоне могло привлечь такое внимание?
Что ж, давайте будем честными, что еще в этом телефоне могло привлечь такое внимание? Камера с разрешением 2 Мп? Дисплей с диагональю 2,4 дюйма и головокружительным разрешением 320х240? Функция Dual SIM? Игра в змею? Ну нет. Новый Nokia 3310 - это просто еще один телефон с клавишами. Это не первый телефон на рынке с цветным дисплеем, он не пионер мобильной фотографии и не выдержит взрыва ядерной бомбы. Ох, обычная клетка. Что это такое толстое, как у Земли?
Что это такое толстое, как у Земли? Нет! Какова поверхность? Какие типы функций есть? Вулканы, кратеры и ручьи. 2. Обсудите проблемы, с которыми столкнутся живые существа на Марсе. Вспомните определение группы для жизни и ее потребностей (четыре требования) из предыдущих действий. Чем Марс отличается от Земли? Меньше, намного холоднее, суше, тонкая атмосфера, ветрено, на поверхности нет жидкой воды и т. Д. Что банки предлагают для родителей кто хотел бы, чтобы все или часть денег, полученных до 500+, были направлены на то, чтобы заработать будущее своего ребенка?
Что это такое толстое, как у Земли? Нет! Какова поверхность? Какие типы функций есть? Вулканы, кратеры и ручьи. 2. Обсудите проблемы, с которыми столкнутся живые существа на Марсе. Вспомните определение группы для жизни и ее потребностей (четыре требования) из предыдущих действий. Чем Марс отличается от Земли? Меньше, намного холоднее, суше, тонкая атмосфера, ветрено, на поверхности нет жидкой воды и т. Д.
Где ошибка сидит, потому что я проверяю пятый раз, и она все равно выходит?
И как это будет выглядеть в случае судебного разбирательства?
Откуда разница в шаблонах?
Вот когда появляются различия и повторения - где мы можем пойти не так?
Или стандартное отклонение также?
При определении цены продажи необходимо учитывать следующие вопросы: Какую цену покупатели готовы платить за товар?
Какова цена других поставщиков, предлагающих аналогичный продукт?
Что такое конвергенция колес и как это влияет на нашу машину?
Что такое схождение колес?